Given the large amount of work that has been undertaken with regard to manipulating printed music using the computer, as surveyed in chapter 2, it is apparent that there is a significant need for an automatic acquisition system. The large number of applications which this would make possible include automatic production of individual players' parts from an existing printed score, editing of existing printed material and production of braille music scores. The possibilities will be detailed and discussed in section 3.3.
It has been seen in chapter 2 that music data entry can usefully be achieved either by using an automatic pattern recognition system or by optimizing the man-machine interface of an operator-driven system. For purely economic reasons the former is preferable, especially when considering large scale conversion of existing printed material into computer-manipulable form. It is interesting to compare a parallel project in the field of text. The production of the Thesaurus Linguae Graecae (a database of classical Greek literature containing 62 million words) was achieved using manual entry in South Korea and the Philippines [Helgerson 1988], similarly, the electronic form of the New Oxford English Dictionary (N.O.E.D.) was produced manually [Weiner 1987]. It must be borne in mind, however, that the availability of people skilled in fast entry of text using a standard QWERTY keyboard is
-50-
far greater than those skilled in entry of musical information, by whatever means. Automatic text reading machines were investigated as an option for the N.O.E.D. project, but rejected on the grounds that the wide range of fonts and poor quality of the images involved were beyond the scope of what was then available [Weiner 1987], and, indeed, would still present a formidable challenge today. Also to be considered, following the recent growth in use of desktop publishing, is the availability of desktop scanning equipment and in conjunction with this, OCR (Optical Character Recognition) software capable of reading commonly used fonts and in some cases 'learning' new fonts. Now that automatic text input (at least of 'standard office fonts') is so widespread, there will be more demand for acquisition, using the same equipment, of information contained in various other forms of binary image - circuit diagrams, for example, as well as music. Currently, these can be acquired in bit-map form, but the recognition of the constituent symbols is the subject of on-going research. The following sections provide background information regarding pattern recognition of binary images of various types, concluding with a review of previous work on automatic reading of music scores.
3.2 PATTERN RECOGNITION OF BINARY IMAGES
The largest area of research within the field of pattern recognition of binary images is Optical Character Recognition, i.e. automatic reading of text. Software is now commercially available, either incorporated into a scanning device or as a separate product, which will read high-quality material containing
-51-
text in a limited range of fonts and point sizes (e.g. ReadRight [1988]). Additional limitations include restrictions on skewing of the original and the type of printing device used in producing the original. Normally, the technique behind software in the lower end of the market is template matching, where the character under test is compared exhaustively with a set of bit-map images of characters in the system's library. The character with the highest correspondence measure is output. Contrary to this, most research papers deal with structural or feature-based methods; however, recently released OCR systems, particularly the more expensive ones, are implementations of such techniques [Discover 1988].
Pixel-based thinning is a commonly-used method for initial data reduction and, possibly, feature extraction, producing a 'skeleton' of the original image by stripping off boundary pixels. This is a time-consuming process (attempts have been made to improve performance, for example by implementation in hardware or parallelising) which may remove structurally significant portions of the image such as short protrusions, or introduce extraneous limbs or 'hairs'. These faults have to be considered when designing the later stages of a recognition system, leading perhaps to the inclusion of a post-processing stage to remove hairs [Harris et al. 1982]. Once the skeletonising operation is complete, the original image will have been converted into a connected list of nodes (or 'branching points') and segments (or 'strokes') which will then be passed on to the recognition stage for identification of 'features - arcs, lines, holes, etc [Pavlidis 1983].
-52-
Alternative methods for thinning or vectorisation have been suggested, including using the polygonal approximation to the contours of an image [Meynieux et al 1986] or using the line-adjacency graph (LAG) of an image [Pavlidis 1982]. Those methods aimed at processing just line-work can be separated from those intended to produce, in addition, a structural description of regions and miscellaneous filled shapes. Work directed towards reading general office documents needs to take this capability one stage further. This would entail the distinction of grey-level or colour regions from binary graphics and then further division of the latter into text - to be forwarded to an OCR module - and graphics - to be vectorised or processed by a recognition module appropriate to the type of image involved [Maynieux et al. 1986, OmniPage 1988].
Obviously a recognition system for printed music must be able to describe blobs (e.g. filled noteheads) as well as line-work (barlines, stavelines, etc.). After approximating the contours of an image with polygons, Maynieux et al. [1986] matched pairs of segments from this outline which were below a threshold for spacing (i.e. the maximum line thickness), and roughly parallel, in order to find lines. Segments which could not be paired in this way had, therefore, to delimit non-linear regions. Much use has been made of the LAG (and transformed LAG) as a basis for thinning or feature extraction. Applications include reading English text [Grimsdale et al. 1959, Hättich et al. 1978, Duerr et al. 1980, Pavlidis 1986, Kahan 1987] and Chinese characters [Badie 1985], analysing electrical circuit diagrams [Bley 1984] and counting asbestos fibres [Pavlidis 1978]. This is also the basis of the
-53-
music recognition system described in chapter 4. The LAG is derived from a run-length encoded version of the image. Nodes of
the graph are formed by continuous runs of black pixels and branches link nodes which are in adjacent columns and which
overlap. The graph can then be used directly in a similar way to a
skeleton, or various rules can be applied to the nodes and branches, agglomerating or removing these to produce a transformed LAG. More details of the latter technique are given in chapter 4.
The use of context is another variable in the text recognition process. Wolberg [1986], for example, did not make use of context, so that a 'superior' system could be produced when contextual information was supplied. On the other hand, Hull and Srihari [1986] used context at the word level in a procedure termed 'hypothesis generation'. For each word a set of extracted features were used to select a subset of words from a given vocabulary. This subset should have contained a correct match for the original word. A 'hypothesis testing' stage - implemented as a tree search - discriminated between the words in the subset using inner features' i.e. features located (spatially) between those used in the hypothesis generation stage.
In general, pattern classification is achieved using either a statistical or structural approach [Baird 1986]. In an effort to benefit from the advantages of both these methods whilst avoiding their disadvantages, some researchers have made use of composite approaches. Duerr et al. [1980, Hättich et al. 1978] used a hierarchical approach consisting of four stages, the first statistical, followed by two structural (the first of these making
-54-
use of a transformed LAG, as mentioned previously and the 'mixed' last stage made the final classification in conjunction with results from the earlier stages. The reasoning here was that patterns exhibit both 'characteristic structures' and 'probabilistic deformations'. Pavlidis [1983] used a different form of combined approach. A structural technique was used for character decomposition in order to cope with wide variations in the input, but the results of this were not passed to a syntactical analyser as might be have been expected; instead a binary feature vector-based statistical classifier was used. This was because the large number of classes involved in an OCR system designed to cope with a variety of fonts and sizes (in addition to Greek characters, mathematical and technical symbols, and 'possibly hand printing') rendered the former approach impractical.
The recognition of Chinese and/or Japanese characters is a different form of text recognition, with its own variety of approaches. As referenced previously, Badie and Shimura [1985] used a transformed line adjacency graph, in their case to extract line segments from handprinted Chinese characters. They cited the problems with hairs and various distortions of conventional pixel-based thinning as their reason for using a LAG-based approach, and relied on a set of heuristics to perform the final classification of line segments. In the work of Tsukumo and Asai [1986], which dealt with machine-printed Chinese and Japanese characters, numerous horizontal and vertical scanning lines were used and features built up from the number of strokes crossed by these lines. In contrast to these stroke-orientated approaches,
-55-
Feng and Pavlidis [1975] decomposed the polygonal approximation to the boundary of each character into simpler shapes - convex polygons, 't' shapes and spirals. They proposed that recognition could then be achieved either by producing feature vectors derived from the characteristics (or simply presence or absence) of certain shapes or by using a graph structure processing scheme. Interestingly, results were also given for processing chromosomes, in addition to Chinese characters, showing the method to be equally applicable.
The recognition of mathematical formulae is another form of text recognition. In addition to the standard alphabetic characters, symbols such as '+', '-' '*', '/' and parentheses are used, as are various point sizes (for example integral or summation signs in appropriate circumstances). Recognition of mathematical formulae is a 2-D problem, a characteristic it shares with automatic reading of music scores, unlike ordinary OCR of text strings which is commonly 1-D (see Byrd 1984, section 2.4, for a comparison between the complexity of mathematical formulae, Chinese documents and music notation). In the work of Belaid and Haton [1984] a syntactic approach to this problem was used, whereby a high priority operator in the formula under examination was chosen as a starting point, and its operands were then broken down iteratively until terminal symbols were reached. A list of rules defining the grammar of a subset of possible formulae was used in this analysis. Although this work used input from a graphics tablet, the above approach could equally be applied to an image-based system.
-56-
Engineering drawings of both mechanical and electrical varieties have been the subject of a significant amount of pattern recognition research [Pferd 1978, Clement 1981, Bunke 1982, Bley 1984, Okazaki 1988]. Clement [1981] used a low resolution scan to find line-work, rather than using the full resolution of the scanner over the entire image area, given that a large proportion of this would commonly be background. It was then proposed that remaining portions of the drawing would be scanned at full resolution in order to achieve raster-to-vector conversion of more complex structures and, where appropriate, character recognition. Pferd and Ramachandran [1978] reviewed scanning and vectorisation techniques and described their LAG-based algorithm for converting run-length encoded images of engineering drawings into vectors. They saw the conversion of the vector representation into a CAD database as 'desirable' but not 'essential' given that significant data compression had been achieved and editing (of the vector list) enabled.
Bley [1984] used a transformed LAG in order to segment circuit diagrams. The resulting graph was split into 'large' and 'small' components, the former consisting of line-work and large symbols, and the latter the legends, i.e. text contained in the diagram. Small components were clustered, forming associated characters into words ready for passing on to an OCR stage. After 'dominant line elements' had been extracted, the remaining large components were processed using 53 'production rules' which analysed and modified the transformed LAG in order to produce the final vectorisation. Bunke [1982] introduced the attributed, programmed graph grammar as a means of interpreting previously
-57-
vectorised circuit diagrams and also flowcharts. A graph representing the input diagram was processed using a set of 'productions'. These transformed the graph, either performing error correction of the input, for example, removing extraneous short line segments, bridging gaps in lines, etc., or producing the output representation for a particular symbol. These transformations made use of attributes of the nodes and edges in the original graph (spatial relationships, line lengths, etc.) together with 'applicability predicates', which specified constraints on the attributes, and were in turn 'programmed' by a 'control diagram' which determined the order of application of the productions.
In a recent paper, Okazaki et al. [1988] used a loop-structure-based recognition process in reading circuit diagrams. Nearly all logic circuit symbols contain at least one loop, i.e. a region of background completely surrounded by line-work. A few do not: resistors and earth for example, and these were dealt with separately. Loops were detected in the original diagram and, for each loop, an appropriate bounding window (termed a 'minimum region for analysis' or MRA) was determined within which testing could take place in order to achieve recognition. A hybrid method was used for this, combining template matching of primitives,
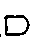 and
and
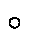 for example, and feature extraction, using the number of connecting lines, the number and size of holes, etc. Production rules were used to mediate between the sets of results derived from the two approaches. These divided into inference rules, where a candidate result was obtained despite the above processes producing different results, and test
for example, and feature extraction, using the number of connecting lines, the number and size of holes, etc. Production rules were used to mediate between the sets of results derived from the two approaches. These divided into inference rules, where a candidate result was obtained despite the above processes producing different results, and test
-58-
rules, where a recognition result was checked for various
parameters before being output. Symbols which did not contain loops were recognised by line tracing from end and corner points,
and matching structural features (branch, corner and end points) using a graph structure representation. In addition to reading symbols with and without loops, line-work and rectangles (macro gates), the system read text which was defined as consisting of freehand characters in the OCR font.
Recognition of hand-drawn diagrams has also been widely researched. Sato and Tojo [1982] used line-tracking as the basis for a system which interpreted freely-drawn circuit diagrams and flowcharts. Initially, by using a coarse scan, the average line width and minimum line spacing were determined. Then, using these measurements, a tracking window was set up, which was used in the line-following process. If black pixels were found at the edge of the window during line-following, the region in question was termed 'complex' and was saved on a stack for later, detailed, analysis. Complex regions included bends, branches, crossings, arrow marks (in flowcharts) and dots. After line-following was complete, arcs and straight line segments were distinguished. Relations between detected primitives (lines, arcs, circles and dots) could then be analysed and symbols recognised according to a priori knowledge of the structure of permitted symbols.
Suen and Radhakrishnan [1976] concentrated on reading hand-drawn flowcharts consisting of boxes constructed from straight lines, interconnecting line-work and associated arrows. Following initial thinning, a run-length encoding-based method was
-59-
used, in this case for horizontal line detection. Line tracking was then undertaken from the ends of each horizontal line, and the direction of these new lines was quantized into one of six possible directions. This was sufficient to distinguish all but two categories of symbol (which required one extra test) while the diamond-shaped symbol was treated separately as it does not contain a horizontal line. The interconnecting lines could then be traced and associated directions determined using a priori knowledge of the number of permitted connections to a particular type of symbol and recognition of the requisite arrows. This information was then output in tabular form and it was proposed that, with the addition of a character recognition capability, a flowchart alone could be used for program input.
Furuta et al. [1984] also made use of run-length encoding, but in processing hand-drawn piping and instrument diagrams. Once a portion of line-work was detected (a group of runs which were below the threshold for maximum line thickness and which did not form an arc or bending point), line tracking commenced. When either the line thickness increased suddenly or exceeded the line thickness threshold) a bending point was encountered, or no continuation of the line could be found after traversing a break, a symbol was deemed to exist. Geometrical feature points were used in order to achieve symbol recognition. These included end, corner and branch points, filled regions and isolated points. Noise removal and line extraction were also performed and then feature vectors built up, using the number of occurrences of each type of geometrical feature point, the number of lines, etc. A measure of similarity between the vector under test and that of each
-60-
'standard symbol' was calculated and used in conjunction with a threshold in order to complete the recognition process.
3.3 PREVIOUS WORK ON PATTERN RECOGNITION OF PRINTED MUSIC
In the field of pattern recognition of printed music, the earliest recorded work is that of Pruslin [1967] at M.I.T.. This work was followed up by, and to a limited extent continued by, Prerau in the late 1960s and early 1970s [Prerau 1970, 1971, 1975]. A third worker at M.I.T., Mahoney [1982], pursued work in the same area more recently, as part of an undergraduate project.
Further research on this subject has been undertaken by Japanese workers. Matsushima et al. [1985a, 1985b, 1985c] produced the vision system for the WABOT-2 keyboard-playing robot and have subsequently integrated a braille score production facility into their system [Hewlett 1987, 1988]. Nakamura et al. [1979] developed a score-reading facility as a means of acquiring data which could then be used in forming a database for use in work aimed at analysing Japanese folk-songs. Aoyama and Tojo [1982, Tojo and Aoyama 1982] also developed a score-reading system as a means of entering information contained in existing sheet music into a database.
Other research work in this area, although apparently of a short term nature, has also been reported by Wittlich et al. [1974], Andronico and Ciampa [1982], Tonnesland [1986], Martin [1987] and Roach and Tatem [1988].
-61-
Work along similar lines by Gary Nelson and Terry Penney [Nelson 1973b], i.e., 'translating films of printed or handwritten music into numeric data suitable for analysis by computer,' has not been reported in detail.
Two publications by Michael Kassler [1970a, 1972] concerned automatic recognition of printed music. The first of these, 'An Essay Toward the Specification of a Music Reading Machine', went some way towards laying out what the machine should be able to recognize and included an original representational language. The second, 'Optical Character-recognition of Printed music: a Review of Two Dissertations', discussed the work of Pruslin and Prerau. A summary and discussion of Pruslin's work appeared in 'Recognizing Patterns' [Eden 1968] which put the music recognition problem in the context of other pattern recognition work.
The following paragraphs discuss the above work in more detail.
3.3.1 Background
The aims of researchers mentioned above ranged from forming a database (Aoyama and Tojo, Nakamura et al.) to providing a robot vision system (Matsushima et al). The work of Pruslin and Prerau was intended to achieve limited symbol recognition in order to enable general applications. In contrast, Mahoney and Roach and Tatem concentrated on the problem at a lower level, recognising symbol components. A significant proportion of the effort of Pruslin and Prerau was targeted, however, on the specific aspects
-62-
of note-cluster detection and staveline extraction respectively.
All three M.I.T. authors mentioned the distinction between musical symbols which can be treated as characters (because they are the same on each appearance) and those which have varying graphical parameters, such as slurs. Pruslin treated notehead clusters as characters, but beaming complexes as varying combinations of parallelograms. Prerau gave special attention to the problems of recognising non-character symbols whilst Mahoney's approach of detecting primitives, rather than complete symbols, partially solved this problem.
A question of terminology arises when comparing the aforementioned works. Prerau coined the term 'sofon' (Sharp Or Flat Or Natural) to describe the sharp, flat or natural sign in any context, as opposed to using the term 'accidental' which, strictly, implies an alteration of the pitch of a note, compared to either its previous occurrence or the current key signature. In this thesis the term accidental will be used in the strict sense of the word, to refer to one of :- sharp, double sharp, flat, double flat or natural.
3.3.2 Aims
The aims of the aforementioned researchers varied widely. Prerau aimed to produce a program which could be expanded easily given that his work could not be comprehensive, while Mahoney emphasised design, thus presenting the basis for a 'real' system. He advocated retaining as much textual information as possible so
-63-
as not to favour a particular representation scheme, and measured the usefulness of a music recognition system by its flexibility (ability to cope with variations in style and print quality). An important point which Mahoney mentioned in outlining his research philosophy, which will recur in chapter 4, is the trade-off which exists between robustness and simplicity of the recognition task.
Nakamura et al. aimed to produce a database of Japanese folksongs in order to study and manipulate these, as sound and printed score, using a computer. Aoyama and Tojo also aimed to produce a database, but of more general material, and as part of an interactive music editing and arranging system. In contrast, Roach and Tatem's work was prompted by the economics of music publishing, where a large amount of money is spent on converting composers manuscripts into engraved notation.
3.3.3 Acquisition (scope of input material, scanning and thresholding)
The scope of the input material also varied. Pruslin asserted that complete recognition was achieved when the type, order, volume, tempo and interpretation of notes were specified, but his work only attempted to recognise solid noteheads and beaming complexes, as well as determining note order, in single bars of piano music.
Prerau used a flying-spot scanner to digitise samples consisting of two or three bars of a duet for wind instruments taken from Mozart K.487. The scope of his work was defined as an
-64-
engraved sample of standard notation, where this was taken as 'most instrumental and vocal music between the end of the 17th century and the beginning of the 20th century'. Recognition was limited to that notation which needed to be recognised in order to enable a performance of a minimal version of the score. That was, notes of all types, rests, clefs, time signatures, key signatures accidentals, and dots, but not dynamics, tempo markings, ornaments, etc. The source material was chosen to contain all basic notational symbols while being relatively simple. Duets were chosen because they provided structural features of larger ensembles whilst using single-note-per-voice notation. The latter requirement was stipulated, ostensibly, to lessen the overlap with Pruslin. The point was emphasised that the source music (K. 487) was from an ordinary book, i.e. not specially prepared for computer input. The samples used were 1 1/2" x 1 1/2", i.e. two to three bars of the duet music digitised at a resolution of 512 x 512 pixels over the total image area of 2 1/4" x 2 1/4", giving approximately 225 d.p.i.. These were grey-scale images and the threshold was chosen 'by eye' to give staveline thickness of approximately three pixels, given that 'any thinner line would run the risk of having breaks in stavelines. Since staff-line continuity is an important property used in the isolation section, staff-line breaks are to be avoided.' Unfortunately, staveline continuity cannot be relied upon, as will be seen in chapters 4 and 5.
Andronico and Ciampa also used a flying-spot scanner, 'with negatives of 24mm x 36mm at 512 x 512 resolution with 64 grey levels. Binarisation was achieved using a manually selected
-65-
threshold, although the use of automatic thresholding was a future aim.
Mahoney mentioned that the highest possible resolution, although desirable, was likely to produce prohibitively large images. Also, he used no preprocessing in order to reduce the effects of noise, because the greatest difficulties were usually inherent in the printed text itself. The worst case of this is perhaps provided by the breaking up of a symbol which needs to be connected guitar music. Resolution of 100 microns (254 d.p.i.) was used to produce a 256-level grey-scale image. This was then thresholded by setting all pixels with value greater than zero equal to one.
The WABOT-2 vision system (the work of Matsushima et al.) required real-time recognition using images from a video camera, sometimes derived from distorted music sheets. Single A4 pages of electronic organ score containing relatively simple notation using three stave systems provided the source material. The method of image acquisition led to variations in the image due to position and characteristics of the light source, camera tilt and resolution, in addition to distortions of the sheet of music and inconsistencies in the notation itself. The CCD camera produced images of 2,000 x 3,000 pixels with 256 grey levels in approximately two seconos, with the score situated about one metre
-66-
from the camera. The image was subdivided and each region separately thresholded to allow for uneven illumination. The image was then rotated as required and normalised to compensate for distortions introduced at the scanning stage.
The scope of Aoyama and Tojo's system covered single melody lines and more complex scores incorporating multiple voices. The size of the music was free within certain limits and, to some extent, distortion, blurring and breaks in stavelines were permitted. A drum scanner with the same specification as that of Mahoney (i.e. 254 d.p.i. resolution and 256 grey levels) was used, enabling entry of a complete page, whilst avoiding the problems encountered by Matsushima et al. in using a video camera. Two scans were used; the first provided several blocks of widely spaced scan lines which were used in determining the binarisation threshold and staveline location, while the second was the complete high resolution scan. The page was, however, broken up into windows for processing. This is contrary to the structure of a large amount of music and is a major limitation when processing multi-stave systems and symbols which straddle two staves or fall on a window boundary. Each of the windows contained a single stave and was stored in run length encoded form - an approach used by Wittlich et al.
Nakamura et al. dealt with monophonic music in the form of Japanese folk-songs. The vocabulary of symbols covered included notes, rests and accidentals. A CCD-array-based scanner was used for image acquisition and some smoothing of the image was attempted as part of the binarisation procedure.
-67-
Roach and Tatem worked with a full page greyscale image at 1200 x 800 pixels (equivalent to 100 d.p.i.), and some smaller images containing a limited range of symbols, and aimed to extract pitch and duration information.
Wittlich et al. also used a flying-spot scanner, in their case to produce a single image (1200 vertical x 1000 horizontal pixels) of a page of Debussy piano music.
3.3.4 Staveline location and segmentation
Finding the stavelines in an image is a prerequisite of recognition of conventional music notation. It is also a non-trivial task, a point emphasised by several workers. Prerau pointed out that segmentation of individual symbols was more complicated for music than for character recognition. Only occasionally do letters have to be separated in OCR, when the text in an image is of poor quality. In his work, 'about as much effort went into isolating the symbols as went into recognising the isolated symbols.' Also, on the same subject, he drew attention to the important fact that 'the original five stavelines are generally not exactly parallel, horizontal, equidistant, of constant thickness, or even straight.' Pruslin simply removed thin horizontal lines by thresholding the length of continuous vertical runs of pixels, assuming that a figure for 'line thickness' was known. This approach prevented Prerau from achieving his intended aim of expanding Pruslin's work, because it distorted symbols and prevented their recognition. Both Pruslin and Prerau used contour
-68-
tracing, the latter in his own method for separating symbols from the stavelines, termed 'fragmentation and assemblage'. This involved a contour trace proceeding along each edge of each staveline in turn and when the gradient exceeded 1:l0, a 'deviation point' - the start of a fragment - was deemed to exist. A 'staff-line border' was then set up. This was a horizontal line, starting from the deviation point, which formed the edge of the fragment where, originally, it touched the staveline. The contour of the complete fragment could then be found. Fragments were given type numbers according to the number and position of the stavelines (if any) to which they were connected. Fragments which did not touch a staveline had to be found using a separate, somewhat laborious process involving finely-spaced search lines which spanned the page. The fragments were then assembled using a criterion which assumed horizontal overlap, so as to reconstitute the symbols but without the stavelines present in the original. Unfortunately, this criterion is not always satisfied, for example, where a symbol such as a shallow slur or bass clef coincides with a staveline, it may be fragmented.
Instead of using the approach taken by Prerau, i.e. removing the stavelines and then restoring those parts which coincided with symbols, Andronico and Ciampa devised a technique which aimed to remove just the exposed stavelines. No details of the staveline recognition method were given, although it was mentioned that successive trials' were used in searching for the stavelines and that the number of iterations required was proportional to the amount of background noise.
-69-
The isolation of symbols from stavelines was an important objective of Mahoney's work. He singled out lines, both straight and curved, as predominating in common music notation. Also, he stated that lines could be described by their run-length encoding in conjunction with collinearity and proximity constraints for dealing with gaps. Line extraction was described as 'easy' given the above line encoding, but details of the process used were not given. Regions which were not lines were found as 4-connected components by flood-filling [Duda 1973]. With regard to staveline processing, Mahoney mentioned permissible gaps in lines, where symbols were superimposed, and suggested interpolation between end-points. Similarly, close ledger-lines from adjacent notes may have been treated as a single line by his method, but apparently harmlessly Other problematic configurations which Mahoney mentioned included two open noteheads either side of a staveline, the F-clef and time signatures, all of which are examples of situations where portions of symbols coincide completely with stavelines. The minims (or semibreves) could be detected, he asserted, by locating the internal white dots, but this presupposes that the black boundary is closed. Replacing short lines after staveline removal was a suggested partial solution for the other two cases, involving the F-clef and time signatures. If a stave or ledger-line passed through a hollow notehead, the above technique could still have been used, once the portion of line within the notehead had been removed. Another situation which was mentioned concerned a note stem in a crotchet chord which would have been treated as ending where it met a close cluster of noteheads. The association of all the noteheads with the stem would have to be achieved nonetheless. Similarly, where the tail
-70-
of an individual quaver touched its notehead, the separate components (notehead, stem and tail) would still have to be isolated. Passing reference was made to the difficulties which arise when beams and stavelines are coincident for any significant distance, thereby disrupting association of staveline segments. A general rider was provided to the effect that 'these situations are not generally handled by the system presented in this thesis.'The stavelines in the scores processed by the system of Matsushima et al. were detected by a short bar-like filter which operated down equi-spaced columns in the image, simultaneously with the scanning process. Pulsed output from the filter indicated the presence of stavelines. (Similarly, Wittlich et al. used a bar-like filter which was available as a function of their scanner.) The points where the presence of stavelines was indicated were joined to form straight lines, and where five equi-spaced lines were found, a stave was deemed to exist. Staveline inclination and curvature, and failed detection all forced a need for flexibility, and similarly, long slurs parallel to the stavelines had to be eliminated by checking vertical spacing.
As already mentioned, Aoyama and Tojo used two scans. The stavelines were found by forming the horizontal histogram of black pixels within each block of low resolution scan lines, and using a threshold to find sets of five peaks. The staveline fragments were then pieced together, line spacings established and line spacings calculated. Coarse segmentation was then undertaken, removing obvious, exposed sections of (stave-)line-work by examining the
-71-
vertical run-lengths involved, but leaving short portions of staveline where these existed in the proximity of a symbol. This was intended to help avoid breaking up minims and the like where they coincided with the stavelines, as the fine segmentation process could examine each symbol or connected symbols more carefully. Both black and white noteheads were detected as part of fine segmentation - by searching for sequences of overlapping vertical runs of pixels - in order to assist in correctly removing remaining staveline fragments.
Roach and Tatem described staveline finding as a particularly difficult problem'. They implemented an existing line-tracking algorithm which calculated line direction and thickness at each pixel in a grey-scale image by passing a window of appropriate proportions over the image. They pointed out that, where a symbol coincided with a staveline, the pixels involved 'belonged' to both, and so stavelines needed to be 'intelligently removed'. The least-squares fit through lines was found and stavelines were identified as horizontal lines stretching across almost the width of the page. Vertical lines were found in a similar way to horizontal lines and then a circularity measure was applied where a 'wide' portion existed at the end of one of these. This was classified as a notehead if its circularity exceeded a threshold. Thinning was used on isolated components to produce chain codes. These were segmented at junction points and arcs with high curvature were subdivided ready for use by the recognition routines. Flood-filling the background (i.e. white pixels) was used to locate 'holes' (small white areas contained within symbols).
-72-
Nakamura et al used manual entry of the starting co-ordinates for a line-tracker which constructed least-squares fit lines for each of the stavelines. Then, as with Wittlich et al and Pruslin, a threshold for line thickness was used to erase the stavelines and achieve segmentation.
The use of a bar-like filter (Wittlich/Matsushima et al) is not only vulnerable to staveline inclination and curvature, but also to the effects of multiple beams or other linear elements
which can be present in a score. Also, short staves containing
realised ornaments, for example, would not be detected. The same applies to the use of a horizontal histogram of black pixels, even locally (Aoyama and Tojo). All these aspects are covered in
chapters 4 and 5.
3.3.5 Grammar and syntax
Prerau provided syntactic rules for a limited subset of music notation as well as mentioning the higher-level grammars which are present in music notation but which were not covered by his thesis. He made use of syntax and redundancies, for example flats could only appear in one of two positions (this excluded those special cases not within the scope of Prerau's work) - in a key signature to the right of a clef or barline, or as an accidental. Also, the clef was the only symbol which could be first in a line of music. Redundancy in music notation was exemplified by the first flat of a key signature having to be on the middle line (assuming treble clef), or conversely, if the first symbol of a
-73-
key signature was on the middle line it had to be a flat. Similarly, Prerau asserted, if the first symbol of a key signature was a flat, then the second symbol in the key signature (if any) had to be on the top space and a flat. Prerau also limited rests to certain vertical positions and supplied constraints for other symbols. Time signatures had to be to the right of a clef, barline or key signature, the triplet indicating numeral '3' had to be overlapped by a beamed group of three notes and dots had to be positioned appropriately for duration augmentation or as part of a repeat sign or F-clef (staccato and other dots were not permitted).
Andronico and Ciampa formulated two generative grammars. The higher order structures of music down to the individual symbols were represented by one grammar and the components of the symbols by the other. Examples of components are vertical lines of various lengths; white and black dots, etc. Similarly, Matsushima et al made use of a simple hierarchical structure for music notation in directing the correlation techniques used for detecting symbols and symbol components. Stavelines, noteheads and barlines, which could occur anywhere over a large area were searched for using hardware-implemented correlation, while other symbols (clefs, rests etc.) were found using software-implemented localised search techniques. The use of a mask to detect crotchet noteheads led to numerous spurious matches which had to be filtered out at a later stage. This problem would inevitably worsen in the case of more complex notation and this shows the weakness of the approach, given that the speed factor is overcome by implementation in hardware. Only treble and bass clefs were permitted in their work,
-74-
and these only at the beginning of a line. Musical syntax rules used in error-detection and correction included the following :- the playing times for each part had to be equal, a clef and a key signature had to begin the opening bar of a part, and, similarly, a time signature had to exist in the first bar of a score.
Aoyama and Tojo used the following syntax rules :- a key signature was only permitted on the right hand side of a clef, the first sharp in a key signature had to be on the fifth line (treble clef), and accidentals had to be on the lefthand side of a note- head. They also compared the sum of the rhythm values of the notes in each bar with the time signature and any discrepancies were used in the error correction procedure. This ignores the problems of n-tuplets where, upon multiple repetition, the associated numeral is omitted, and also mathematically-incorrect beamed groups in cadenza passages. Nakamura et al drew attention to the lack of rigid rules for writing music notation and said that rules used in practice are often based on 'customary usage'. As a result of this, they concluded that it was impossible to check recognition results by using musical grammar and instead relied on man-machine interaction (using the sound and print production facilities of their system) for error-correction.
3.3.6 Object (symbol) formation and recognition
Contour tracing after horizontal and vertical line removal provided the components and their parameters (relative and absolute size and position) for processing in Pruslin's work. As mentioned previously, note cluster detection required a large
-75-
proportion of Pruslin's effort. Twenty-three possible arrangements of notehead clusters made up from less than five noteheads were tabulated and used as the basis for the processing of crotchet chords. This attempt to treat chords as 'character' symbols is severely restricting in view of the prohibitive number of 'models' which would be required for a practical system. The identification process categorised the permutations of noteheads using height and width information. Those clusters with width greater than a single notehead had their contour trace examined in specific columns and the number of black/white transitions determined. The number and position of these crossing points was used in order to achieve classification.
Beaming complexes were characterised as combinations of parallelograms with appropriate restrictions on spacing and extent of subsidiary beams. It was explained that, due to intersecting notestems or stavelines, scanner resolution and/or poor print quality, the constituent parallelograms of a beaming complex may or may not have formed a single contour trace. The principal beam, or 'timing bar base' (in this case the beam on the opposite side of the beaming complex to the notestems) was treated separately, and subsidiary beams were related to it, and the positions of the characteristic transitions in thickness extracted. These jumps were detected by setting a threshold for change in thickness at just less than half the staveline spacing and using this in conjunction with a parameter for permitted horizontal deviation within the thickness transition. Parallelograms (subsidiary beams) which became separated from the main beam as a result of pre-processing were subsequently detected and merged using a
-76-
threshold for permitted vertical spacing. The beaming complex was classified according to whether subsidiary beams were present, and if so, on which side of the principal beam. Finally the slope of the principal beam was calculated.
Operations were subsequently performed with the aim of ordering notes and determining their rhythm values. Ambiguities regarding regions which could still be either note clusters or beaming components were resolved using the fact that the latter had to have related note clusters at both ends. Information regarding the permitted stem direction for each form of note cluster was also used. Pruslin also made use of short horizontal scans on the original image in order to determine whether stems associated with a quaver (i.e. single) beam were above or below, as beam and noteheads alike were 'floating' in free space following the pre-processing. Where note clusters could be attached to either an ascending or descending stem, similar searches were made. The problem of ordering the detected notes was discussed and the unsuitability of simple left to right ordering was analysed. The vertical alignment across staves of note clusters was examined, and the corresponding sequence (timing) information was extracted.
Prerau used the normalised bounding rectangle (normalised relative to the stave space height) to produce lists of possibilities for each symbol, after making the assumption that, unlike alphabetic characters, each musical symbol differed in size from most others. The tests he used which were based on syntax, position and redundancy have been mentioned in section 3.3.5.. When
-77-
these tests failed to remove ambiguities, another type of test was used which involved measuring features. Feature tests were used to distinguish between sharp, flat and natural signs and between the different types of non-beamed notes. An example of such a test involved measuring the width of a symbol at its vertical mid-point, thereby distinguishing a stem-up quaver from a crotchet. Sharp, flat and natural signs were distinguished by finding the horizontal position of the top and bottom-most points of the symbol relative to its bounding rectangle. The procedure for determining the pitch of a note on the stave was not described. Noteheads in a beamed group were found as single-connected fragments, whilst corners of beams that also formed single-connected fragments were detected and removed. Barlines and double barlines were differentiated as follows :- if a barline had at least one hole it was considered double and the stave space where this occurred was tested to ascertain the appropriate combination of thick and thin lines. Hollow and solid noteheads were distinguished by a contour trace which detected the presence of an inner boundary in the former. The pitch of notes on ledger lines was determined by counting the short protrusions on the opposite side of the note stem to the notehead. This is particularly unreliable in practice, as these may not exist (see, for example, figure 5.7). In the case of the note stem being downwards, if the distance from the topmost protrusion to the top of the notehead was greater than 3/4 of the stave space height, the notehead was above the ledger line, otherwise it was on the line. An equivalent procedure was adopted in the case of an up-stem.
-78-
A specific test found the beams of each beamed group. The thickness of the beam component was found at points spaced at intervals of 1/5 of the distance between note stems. These thicknesses were used as follows :- the larger of the first two gave the thickness for the left-hand note and similarly for the second pair and the right-hand note. A thickness up to the stave space height corresponded to a single beam, one to two times this measure equalled two beams, and so on. Unfortunately, where localised measurements such as these are used, noise can severely distort the results.
Andronico and Ciampa's program recognised clefs (of five types), key signatures (using flats or sharps), accidentals and a subset of notes and rests. The brief description of the symbol processing implied that specific points were examined. These were located on the stave/ledger lines and on the mid-points between these lines, in each column of the image. The length of any vertical line segment present at a point was measured and a crude deduction drawn, for example a 'long' line indicated a note with a lefthand stem. The horizontal and vertical position of each symbol was recorded in addition to symbol type and rhythm value, as appropriate. The authors mentioned lack of good results in processing notation half the size of that used for the examples in their paper, but proposed, as a solution, scaling by software-control of the camera which was to be used in future work.
In contrast to the above, the objective of Mahoney's work was to cope with symbol primitives, thus providing the basis for
-79-
recognising composite music symbols in terms of these primitives. For complex symbols (sharp/flat/natural signs, clefs, etc.), which could not be broken down naturally into the above primitives, correct isolation was the sole aim. The work concentrated on extracting the primitives, not on combining them into complete musical symbols. The 2-D relationships between symbols were expressed using proximity and relative position predicates, the former used normalised distance while the latter used left, right, above and below. The measurements used for normalisation were the thickness of the stavelines and the stave space height. Histogramming the lengths of both black and white vertical lines was used to find the normalisation measure; thus, the most common black line length gave the staveline thickness and the most common white line length gave the stave space height. No mention is made however, of different size staves occurring simultaneously in one image. Areas were apparently normalised using the area of the interior of a semibreve, an unreliable measurement given the variability found in this feature in practice.
The parameter list for lines and symbols which Mahoney proposed provides several points of interest and illustrates some drastic limitations of the system. For example, the upper limit for the length of a beam was set at 20 x the stave space height, while the length of a barline was limited to 7 x the stave space height and the permitted angle of rotation for horizontal and vertical lines was +/- 10°. Beams could be within +/- 45° of the horizontal, but with no extra allowance for rotation of the image. Also, notestems were distinguished from barlines by using length, so that a vertical line up to 4.5 x the stave space height was a
-80-
notestem, and above that it was categorised as a barline. A barline was, however, permitted a thickness up to 50% greater than a notestem. After removal of all lines, both vertical and horizontal, individual solid noteheads were detected as isolated regions of the appropriate size. Vertical clusters (chords) of solid noteheads were dealt with by separating out the individual dots by erasing the 'ideal' stave (which consisted of continuous stavelines formed by interpolating between the broken lines extracted from the image) and ledger lines. The individual noteheads could then be recognised, although, as is mentioned, a lower area threshold would be required. A tail and a sharp were also extracted from the test image, as these were the only other types of symbols dealt with by the work.
The correlation techniques used in conjunction with threshold measurements by Matsushima et al. for detecting noteheads, barlines etc., were described in section 3.3.5.. Clefs (treble and bass) were discriminated by the crude technique of measuring in from the start of the stave in two of the stave spaces and comparing these distances. Similarly, time signatures were distinguished by localised measurements effected along the centre-lines of spaces. As mentioned previously, such localised measurements are highly vulnerable to the effects of noise. Accidentals were located by searching to the left of noteheads for vertical lines, and the relative lengths of these lines were used in determining which symbol (sharp, flat or natural) was present. The region surrounding each notehead was checked for the presence of tails, rhythmic dots, and tenuto and staccato marks. Beams were treated by counting the number of vertical black runs in a pair of columns
-81-
equi-spaced either side of the note stem under test.
Aoyama and Tojo achieved recognition using two stages termed coarse and fine segmentation. Initially, the symbols were divided into 10 groups using a normalised feature space (normalised relative to the stave space height) similar to that used ·by Prerau. Separate treatment was then applied to each category in order to achieve recognition. For example, the symbols with the largest bounding rectangles - slurs and beamed groups in this case - were separated by searching for the presence of a vertical component of suitable length (a note stem). The positional relations between noteheads and stems were classified into 10 types, along the lines of Pruslin's technique for dealing with chords mentioned at the beginning of this section, although encompassing polyphonic music where the noteheads of separate parts touched. The latter were separated and then treated individually. As a further example of fine classification, the crotchet rest, quaver rest and sharp, flat and natural signs were divided by a dedicated algorithm. This made use of the effects of erasing portions of these symbols using four preset threshold parameters relating to the width and height of constituent runs of black pixels. The authors drew attention to compound symbols - i.e. those made up of several separate components, the F-clef for example. By examining their relative positions, the different dots involved in the F-clef, the fermata sign, the repeat barline, duration augmentation and staccato could, the authors asserted, be distinguished.
Nakamura et al. reasoned that although musical notes are
-82-
simpler patterns than alphabetic characters, related positional information is more important. Their recognition technique involved extracting characteristics and position information from X and y projection profiles of the symbols after staveline erasure. Projection parameters used included the number and position of peaks, the width of the upper and lower halves of the symbol and the number of 'protrusions' (the 'limbs' extending from the main stem of quaver - and shorter duration - rests and also the tails on single quavers and shorter rhythm values). The position of any notehead present was also extracted.
Roach and Tatem listed some of the problems regarding recognition, particularly of handwritten scores (none of the other authors attempted automatic recognition of handwritten music). Examples were noteheads not closed, stems not attached to noteheads, beams which resembled slurs and ended well away from their associated stems and symbols such as crotchet rests appearing in multiple guises. They argued that even people had difficulty reading some handwritten scores, especially if they did not have the musical knowledge necessary to discern the relevant symbols.
Wittlich et al. achieved recognition of solid notes, beams, slurs and bar lines by examining objects' dimensions, but no details were given.
3.3.7 Interaction and output
Pruslin's output took the form of text descriptions of note
-83-
clusters, including their sequence numbers and rhythm values. 153 clusters were tested and with the template matching threshold set at 70%, only one error occurred. 22 beaming complexes were examined, and all were correctly classified. In contrast, the output of Prerau's system took the form of DARMS (then called Ford-Columbia) data, with the intention that this should act as input to software for analysis, performance, display, printing etc. In the tests performed, output was 100% accurate, i.e. all symbols in the subset considered were recognised, and symbols - e.g. text characters - outside the scope of the program were identified as such. Andronico and Ciampa also produced music representational language encodings, but using TAU2-TAUMUS. They gave output for a single bar which was correctly recognised and also an example of partial recognition due to either incorrect binarisation threshold, poor print quality or presence of symbols which were outside the scope of the work.
Mahoney made use of interaction in developing and refining parametric descriptions of musical symbol primitives and characters (complex symbols) and in determining normalisation factors (this process was termed pre-calibration) which were then applied automatically. A detailed example of the analysis of an image was provided - the output simply taking the form of separate images containing particular categories of primitive or symbol. The vision system for the WABOT-2 robot had to be completely automatic, hence interaction was not an option open to Matsushima et al. For single pages of electronic organ score, complete processing times were given as 'roughly 15 seconds' and accuracy described as 'approximately 100%'. Output used a dedicated M.R.L.
-84-
compatible with the robot's limb control system. Various processing operations were undertaken in order to guarantee that the information passed to the robot control system was permissible and would not cause problems when driving the limbs of the robot (forcing it into attempting to cross hands for example).
Aoyama and Tojo gave an example of output after coarse classification for a single line of two-voiced music (the contents of one of their 'unit windows'), and two small detailed examples of complete analysis. The latter showed the correct separation of notes belonging to separate voices where the noteheads touched, and the distinction between the true tail and a spurious fragment in a stand-alone quaver after removal of thin vertically-orientated lines. In both cases the number and location of heads and beams was provided. An example of data in the format used by the folk-music database of Nakamura et al. was given by them as the result of recognising a few bars of monophonic notation, together with a screen display of the original and its reconstruction in conventional notation, derived from the above data. Pitch (octave number and semitone offset) and rhythm value only were stored.
Roach and Tatem provided a general discussion of the result of processing their six small test images, as no music representational language data was produced. All stave and ledger lines were correctly classified as horizontal lines, as were the centre portion of some long slurs and fragments of noise. Holes were categorised as large or small using the number of constituent pixels and a threshold. Some of the holes were not, as hoped,
-85-
hollow noteheads or part of - a sharp, flat or natural sign, but were formed between a quaver tail and its stem. A significant proportion of the number of noteheads found by the blob detector (applying the circularity measure mentioned previously) had the notehead detected at a lower position than its true one, which meant the wrong pitch would have been assigned. Curves were detected, but only by selecting a threshold for curvature which worked for the test images, but, the authors stated, would not necessarily have been appropriate in the general case. When the writing in the original was poor, problems were encountered with loss of information as a result of segmentation, for example partial beams not distinguished from stavelines. Interestingly, back-tracking was available in some situations, so that the system could try alternatives once its original result had proved incorrect in the light of further data.
3.3.8 Error-checking/correction and future aims
Pruslin made the suggestion that error-correction could be introduced into his software, for example by testing for beaming complex thickness transitions from right to left as well as vice versa, and comparing results. Alternatively, he proposed, increased use could be made of context. He also stated the possibility of expanding the vocabulary of the program as a future aim. This was also Prerau's main concern for the future of his work. In order to extend the vocabulary of his program, a region would have to be added in the normalised feature space for each new symbol, a syntax test devised, and addition made to the output routine of the appropriate DARMS character. Prerau also stated
-86-
that it would be desirable to add the ability to recognise chords - perhaps based on Pruslin's algorithms - and to cope with larger format scores, trios, quartets, and so on. Prerau recognised that piano/organ music presented a more complicated situation (requiring 'a significant effort' in order to extend the software to cope with this sort of score) with symbols crossing from one stave to another, etc. He also proposed that the fragmentation and assemblage method of dealing with 'qualitatively defined interference' (the stavelines) might possibly be useful in other applications.
Andronico and Ciampa also looked to extend the capabilities of their program - to include reading different types of score containing a larger range of symbols, by extending the two grammars used. Mahoney said that expansion of his system to include new descriptions for symbols and formats was possible, and further testing was needed to enable evolution of the system. For instance, musical symbol descriptions needed to be derived from the primitives and the relationships between them. Also, more testing was required in order to define the limits for input quality and recognition accuracy. A convenient image input system was required too, with the inherent trade-off between image size and resolution. Program optimisation, the need for pre-processing and finding a method for dealing with 'complex characters' (clefs, sharp/flat/natural signs, etc) were other proposed topics for future work.
Matsushima et al. did not speculate on future aims, although their work has since involved incorporating a braille score
-87-
production facility into the system [Hewlett 1987, 1988], and a third WABOT is under development [Matsushima 1987]. Text recognition of Italian terms was Aoyama and Tojo's next priority. They proposed the use of the number and size of the constituent letters as a possible method for realising this aim. Nakamura et al, besides expanding the capabilities of their system, aimed to further classify and compare the folk-music contained in the resulting database.
Wittlich et al. originally aimed to expand the vocabulary of their system, but the project was ended due to the large amount of time spent in producing the processing programs, anticipated problems in generalizing recognition routines, and difficulties experienced in obtaining high-quality microfilm [Byrd 1984]. Roach and Tatem did not outline future work, but simply stressed that their results were improved as a result of using domain knowledge in low-level processing - as opposed to the more common practice of applying this knowledge at high level.
-88-